Agradecimientos
Este proyecto debe ser reconocido como una labor conjunta realizada con la Dra. Lorena López Lozada, docente de la Universidad Veracruzana. Lo cual nos brindó su apoyo en el trascurso de la realización de la acción y de la investigación y del material didáctivo que aportó para llevar a cabo este proyecto. Un agradecimiento a la Universidad Vercaruzana, al CONEVAL y al portal de datos abiertos del Gobierno de México. Como un habilitador de la Estradia Digital Nacional apegado a las dispociciones normativas en materia de transparencia y accesso a la información pública. Proporcionando la base fundamental para desarrollar los objetivos propuestos. Y para finalizar, se agradece la cooperación y colaboración de los miembros del equipo por completar con éxito este proyecto.
Resumen
Este trabajo presenta una metodología de aprendizaje no supervisado de Machine Learning específicamente K-medias y análisis jerárquico para identificar el grado de rezago social que presentan los estados de México a partir del Índice Rezago Social. El IRS es una medida que busca diferencias entre áreas geográficas ubicadas en una misma región. El área de interés está habitada por más de 126 millones de personas, asumiendo que son heterogéneas en sus niveles de calidad de vida.
Utilizando el Censo de Población y Vivienda 2020, de un total de 165 observaciones de los 32 estados durante los años 2000, 2005, 2010, 2015 y 2020. Se eligió el año más reciente, trabajando solo con los 32 estados. Con cinco dimensiones (brecha educativa; acceso a servicios de salud; calidad y espacios en el hogar; servicios básicos en el hogar y activos en el hogar) reflejados en 11 variables.Los resultados obtenidos son sorprendentes. Los estados del centro del país se han desarrollado más que los ubicados en áreas fronterizas o en la costa. El uso de dos técnicas óptimas de agrupamiento para clasificar unidades o estados en categorías, con el apoyo del software estadístico R, obtenemos en ambas técnicas una efectividad del 70.4% que tienen las variables independientes a la hora de explicar la variable dependiente.
Un total de 13,217 millones de mexicanos, que representan el 10.3% del total, viven en los tres estados clasificados como de alto rezago social; Guerrero, Chiapas y Oaxaca. En contraste con el 15.4% de la población que viven en los 8 estados clasificados como de rezago social medio, en cambio, los "mejores" 21 estados son; Aguascalientes, Coahuila, Nuevo León, CDMX, Jalisco, Guanajuato, Zacatecas, Chihuahua, Baja California Norte y Sur, Tamaulipas, Colima, Sinaloa, Querétaro, Sonora, Quintana Roo, Durango, Nayarit, San Luis Potosí, Campeche y Yucatán.
Palabras clave: Rezago social, estados/entidades federativas, análisis jerárquico, análisis k-medias, clústeres.
Abstract
This work presents an unsupervised learning methodology of Machine Learning specifically K-means and hierarchical analysis to identify the degree of social lag that the states of Mexico present from the Social Lag Index. The IRS is a measure that looks for differences between geographic areas located in the same region. The area of interest is inhabited by more than 126 million people, assuming that they are heterogeneous in their levels of quality of life.
Using the 2020 Population and Housing Census, out of a total of 165 observations from the 32 states during the years 2000, 2005, 2010, 2015, and 2020. The most recent year was chosen, working only with the 32 states. With five dimensions (educational gap; access to health services; quality and spaces at home; basic services at home and assets at home) reflected in 11 variables. The results obtained are surprising. States in the center of the country have developed more than those located in border areas or on the coast. Using two optimal clustering techniques to classify units or states into categories, with the support of the statistical software R, we obtain in both techniques an effectiveness of 70.4% that the independent variables have when explaining the dependent variable.
A total of 13,217 million Mexicans, representing 10.3% of the total, live in the three states classified as having a high social gap; Guerrero, Chiapas and Oaxaca. In contrast to the 15.4% of the population living in the 8 states classified as having a medium social backwardness, on the other hand, the "best" 21 states are; Aguascalientes, Coahuila, Nuevo León, CDMX, Jalisco, Guanajuato, Zacatecas, Chihuahua, Baja California North and South, Tamaulipas, Colima, Sinaloa, Querétaro, Sonora, Quintana Roo, Durango, Nayarit, San Luis Potosí, Campeche and Yucatán.
Keywords: Social backwardness, states, hierarchical analysis, k-means analysis, clusters.
Introducción
Para hablar de rezago social es necesario hacer referencia al concepto de desigualdad social, que ha sido ampliamente discutido y desde diferentes disciplinas, ya sea en el derecho, económico, social, etc. Algunos autores consideran que las desigualdades sociales son desigualdades naturales, que son presente entre individuos principalmente debido a diferencias en las dotaciones de inteligencia, talentos, recursos físicos y biológicos, siendo por tanto aceptable. Sin embargo, hay otra posición que sostiene que las desigualdades sociales no son naturales, sino por el contrario, el resultado de un proceso de construcción sociocultural.
Las desigualdades sociales no son naturales, sino por el contrario, la resultante de un proceso de construcción socio-cultural. Si bien se reconoce que los individuos están desigualmente dotados de inteligencia, talentos, habilidades, recursos físicos y biológicos, se sostiene que no existe sociedad alguna en la cual estos elementos, en sí mismos, y por definición, constituyan una fuente de diferenciación social y en tanto tales, el fundamento de la desigualdad social. (Facultad Latinoamericana de Ciencias Sociales (FLACSO), 2004).
Podemos reconocer la existencia de diferencias naturales entre los individuos, unas como consecuencia natural y otras debido a las circunstancias o al entorno en el que se desarrollan las personas. Pero esto no debería ser un impedimento para que las personas disfruten de un bienestar estable. Por tanto, es importante asegurar no solo la igualdad de oportunidades, sino también la igualdad de condiciones que permitan a todos los individuos de una sociedad aprovechar al máximo las primeras, y que, por tanto, es el esfuerzo el que determina las posibles diferencias en el bienestar logrado. Habiendo discutido lo que se refiere a la desigualdad y la importancia de promover la igualdad tanto de oportunidades como de condiciones principalmente, es necesario pasar al tema del rezago. Según la Real Academia Española, quedarse atrás implica:
1. tr. Dejar atrás algo.
2. tr. Atrasar, suspender por algún tiempo la ejecución de algo.
3. tr. Reses débiles que se apartan del rebaño para procurar mejorarlas.
4. prnl. Quedarse atrás.
Arguello, A (2012) dice que, el término de rezago social durante varios años no había sido definido de manera clara y uniforme, ya que existen diversos enfoques según los períodos históricos y los diferentes gobiernos, teniendo en cuenta las variables económicas, políticas, sociales, culturales, militares e incluso las morales y religiosas, variando y tomando diferentes connotaciones y dejando de lado los aspectos demográficos por no ser considerados un factor determinante.
El tema del rezago social ha sido ampliamente estudiado, así como su intento por construir indicadores que reflejen la forma en que se manifiesta y que permitan identificar los espacios y sectores de la población que más lo experimentan, dado que la Ley General de Desarrollo Social establece que la medición de la pobreza debe considerar la naturaleza multidimensional de la pobreza, CONEVAL construyó el Índice de Rezago Social, incorporando indicadores de educación, acceso a servicios de salud, servicios básicos, calidad y espacios en la vivienda y activos en el Rezago Social es una medida ponderada que resume cuatro indicadores de carencia social (educación, salud, servicios básicos y calidad y espacios en el hogar) en un único índice que tiene como objetivo ordenar las unidades de observación según sus carencias sociales.
CONEVAL contribuye a la generación de información para la toma de decisiones en materia de política social, especialmente para analizar la desigualdad de cobertura social que persiste en el territorio nacional. Los datos de esta página son los relacionados con las estimaciones del IRS de 2020 a nivel nacional, estatal, municipal y local con base en el Censo de Población y Vivienda de 2020. Por tanto, existe información sobre las tasas de rezago social 2000, 2005, 2010, 2015 y 2020 a nivel federal y municipal.
Finalmente, este estudio constituye un esfuerzo por reconocer las desigualdades sociales, identificando estados de la población que se han rezagado con respecto al desarrollo que ha experimentado México en 2020, bajo la idea de que el País debe promover tanto la igualdad de oportunidades como la igualdad de condiciones, por el bien de una sociedad más justa.
El presente estudio que se propone a continuación tiene como objetivo aplicar una agrupación óptima con un algoritmo no supervisado que permita identificar las áreas prioritarias del país en términos de desarrollo social y así apoyar la toma de decisiones en materia de política social.
Objetivo general
Aplicar técnicas de machine learning no supervisadas para identificar áreas prioritarias en materia de desarrollo social en México a nivel estatal durante 2020 para apoyar la toma de decisiones en materia de política social.
Objetivos específicos
Metodología
El presente trabajo se realizó para identificar y describir el rezago existente en México. El estudio fue de tipo transversal y retrospectivo, ya que se analizó el comportamiento de una serie de variables en el año 2020, esto una vez que los datos fueron obtenidos, procesados y divulgados por el CONEVAL. También fue comparativo pues se compararón los resultados obtenidos a partir de distintas técnicas de agrupamiento no supervisado (k-medias y agrupamiento jerárquico).
Los datos correspondientes para este estudio se derivaron del Censo General de Población y Vivienda, México, que publica el INEGI. De un total de 165 observaciones de las 32 entidades federativas durante el año 2000, 2005, 2010, 2015 y 2020. Se optó por el año más reciente y se trabajó con las 32 entidades (observaciones). Con cinco dimensiones previamente mencionadas (rezago educativo; acceso a los servicios de salud; calidad y espacios en la vivienda; servicios básicos en la vivienda y activos en el hogar) reflejadas en 11 variables.
Estos indicadores tienen variaciones a lo largo del territorio nacional, es decir, se observan diferentes niveles al comparar entre entidades federativas, municipios y localidades, disimilitudes que son capturadas por el IRS. De lo anterior se deriva que el IRS permite identificar las desigualdades regionales en el nivel y grado de rezago social.
Método de selección de variables:
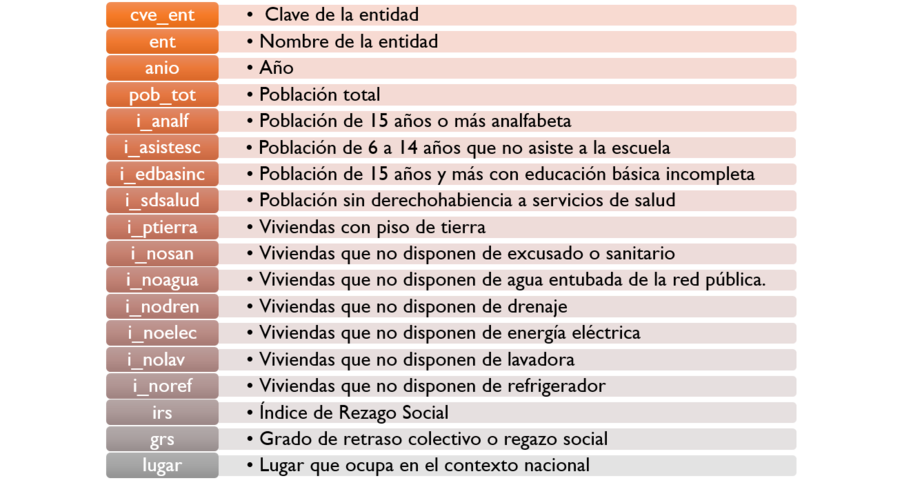
El índice incorpora información de 11 indicadores relacionados con educación, acceso a servicios de salud, servicios básicos de la vivienda, calidad y espacios en la vivienda, y activos en el hogar, y fue calculado a partir de las variables arrojadas por el Inegi en el Censo de Población y Vivienda 2020. Las variables a emplear son:
1. Población de 15 años o más analfabeta.
2. Población de 6 a 14 años que no asiste a la escuela.
3. Población de 15 años y más con educación básica incompleta.
4. Población sin derechohabiencia a servicios de salud.
5. Viviendas particulares habitadas con piso de tierra.
6. Viviendas particulares habitadas que no disponen de excusado o sanitario.
7. Viviendas particulares habitadas que no disponen de agua entubada de la red pública.
8. Viviendas que no disponen de energía eléctrica.
9. Viviendas particulares habitadas que no disponen de drenaje.
10. Viviendas particulares habitadas que no disponen de lavadora.
11. Viviendas particulares habitadas que no disponen de refrigerador.
La elección de las 11 variables con las que se trabajó (cuantitativo-continuo en una escala de medida de razón) obedeció en primer lugar a su disponibilidad, y en segundo a que representan carencias de cada una de las 5 dimensiones que debieran estar ya superadas debido a que los derechos a la educación, a la salud, a la vivienda digna y a un empleo formal y bien remunerado, se encuentran plasmados en la Constitución de nuestro país y en la Declaración Universal de los Derechos Humanos, buscando así asegurar un nivel mínimo de condiciones en la calidad o nivel de vida de las personas.
Análisis estadístico
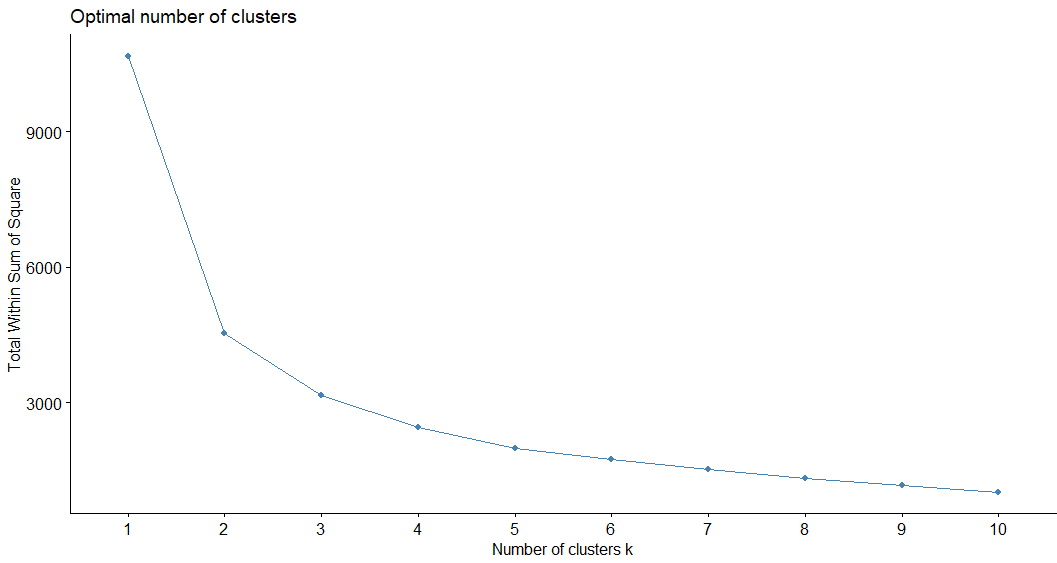
De acuerdo con los objetivos específicos que se establecieron, para la primera parte se utilizó estadísticas descriptivas y algunas gráficas a fin de conocer de manera general las principales características sociales de México y posteriormente hacerlo a nivel estatal, así como revisar que no haya datos faltantes o detectar outliers e identificar la variable respuesta para el estudio. Como complemento de este apartado se implementó la técnica k-medias donde se usó la matriz original y con datos escalados con el fin de determinar quién brinda el mejor resultado, se asumió que no hubo diferencia significativa, ya que todas las variables son continuas dentro de una misma escala, se analizó y se llevó a cabo la matriz de distancias. Posteriormente, se determinó la matriz a utilizar con n clústeres, se observó la distancia que tiene cada grupo con respecto al centroide con la suma del cuadrado de los grupos conforme al conglomerado. Finalmente, se realizó una representación gráfica de los grupos con su varianza explicada en dos dimensiones.
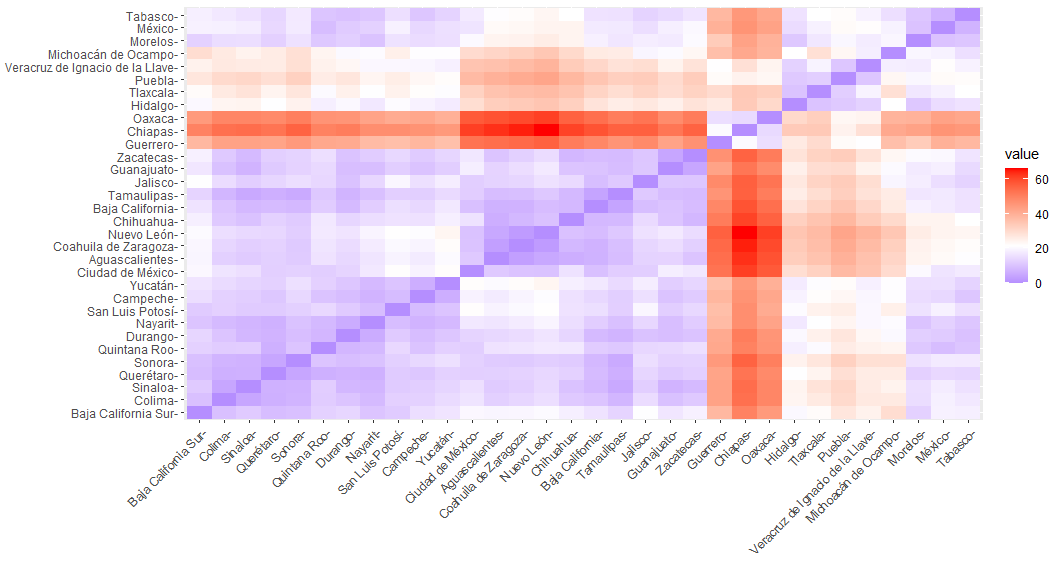
La segunda técnica, la de agrupamiento jerárquica, se aplicó con el objetivo de identificar las entidades federativas con mayor rezago. Para ello, la información se analizó con una técnica estadística multivariante (análisis clúster), su objetivo es agrupar objetos formando conglomerados de objetos con un alto grado de homogeneidad interna y heterogeneidad externa, que permitan mostrar la asociación entre las variables que van a configurarlo.
Al formar los clúster o grupos se busca cumplir que cada elemento pertenezca a uno, y solo uno, de los grupos formados; que los objetos dentro de cada grupo (conglomerado) sean similares entre sí (Chue, Barreno y Millones, 2008, pp.54). Dado lo anterior, se realizó análisis clúster; el primero para clasificar a las entidades federativas en función a sus similitudes con respecto a variables vinculadas a su grado de rezago social. En consonancia con lo anterior, para el análisis clúster se implementó el tipo de enlace Ward y medida de distancia euclidiana, para realizar dicho análisis se empleó el software R.
Los 3 estratos o grados de rezago social en que se distribuyen las unidades de observación, de acuerdo con su Índice, son: alto, medio y bajo rezago social. Se realizó la prueba de hipótesis estadística para ver qué tan bien se ajusta el conjunto de observaciones al agrupamiento estadístico aplicado, con ayuda del valor de Stress se obtuvo un 70.4 %. Lo cuál indicó una buena representación del agrupamiento de las observaciones originales.
HIPÓTESIS: La hipótesis planteada fue que los estados o entidades federativas localizados en el centro del país se han desarrollado más, que aquellos ubicados en zonas fronterizas o en litorales.
BASE DE DATOS
CONEVAL, Consejo Nacional de Evaluación de la Política de Desarrollo Social, 2020, Índice de rezago social publicado en Internet.
Resultados
En el análisis k-medias se empleó la matriz original con 3 clústeres perfectamente definidos, obteniendo una varianza explicada por los grupos formados de 78.9 %. La primera dimensión explicó un 67.3 % de la varianza ubicada en el eje "X", la segunda dimensión explicó un 11.6 % de la varianza ubicada en el eje "Y", donde el grupo uno y dos están representados en rojo y verde respectivamente, existe mayor relación positiva dentro de estos dos grupos. Como puede verse, con k = 3 el modelo asigna clases consistentes a los datos originales, especialmente al observar las agrupaciones que existen en toda la zona de la gráfica donde los grupos son evidentes, se observa que la distribución de puntos es adecuada para cada grupo.
Al incrementar el valor de k, se obtuvo agrupamientos que recopilan partes específicas de los datos de entrada, incluso llegando a dividir en dos grupos distintos a lo que inicialmente parece ser un solo grupo, cuando k = 4 y k=5, comienzan a surgir traslapes en las agrupaciones. Así, vea cómo el algoritmo de K-medias es capaz de producir de manera natural estos agrupamientos a partir de las semejanzas de los datos, y dichas clases generadas de hecho concuerdan con la intuición propia al observar los datos escalados y los datos de entrada.

En el análisis jerárquico, los datos no se particionan en un clúster en particular en un solo paso. En su lugar, tiene lugar una serie de particiones, que pueden ejecutarse desde un único clúster que contiene todos los objetos, hasta n clústeres que contienen un solo objeto (Gonzalez, 2018). La agrupación jerárquica se realizó con diferentes tipos de enlace: el enlace completo utiliza la distancia euclidiana, enlace promedio, enlace simple, enlace centroide y enlace Ward. El resultado del diagrama bidimensional o dendograma mostró que la agrupación jerárquica mediante la agrupación de varianza mínima de Ward explicó de mejor manera los grupos formados por 3 clúteres, sorprendentemente agrupó las entidades federativas de la misma forma que el análisis k-medias, obteniendo una varianza explicada por los grupos formados de 78.9 %. La primera dimensión explicó un 67. 3 % de la varianza ubicado en el eje "X", la segunda dimensión explicó un 11.6 % de la varianza ubicado en el eje "Y". Mira y compara.
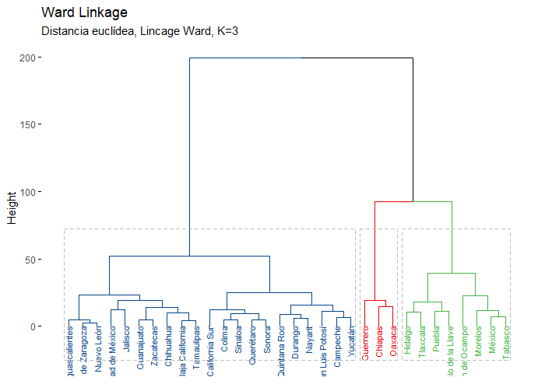
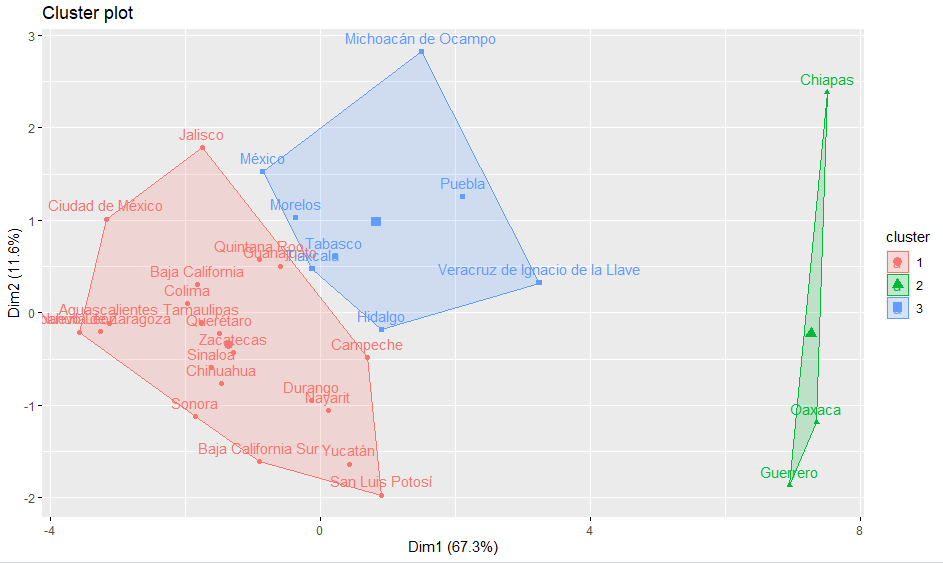
Ambas técnicas de aprendizaje no supervizado (análisis k-medias y análisis jerárquico) realizaron la misma agrupación, 3 grupos de 3, 8 y 21 entidades federativas. Grado de rezago social alto, medio y bajo, respectivamente.
MAPA DEL REZAGO SOCIAL EN MÉXICO 2020
Entidades federativas con grado de rezago social alto, medio y bajo.
Mapa interactivo elaborado con el software R
Discusión
El Consejo Nacional de Evaluación de la Política de Desarrollo Social (Coneval) dio a conocer los resultados de las estimaciones correspondientes al Índice de Rezago Social (IRS) 2020. De acuerdo con las estimaciones del Coneval, Chiapas fue la entidad con mayor rezago social en 2020, mientras que Nuevo León fue la que presentó el menor rezago. Los otros tres estados con mayor rezago fueron Oaxaca, Guerrero y Veracruz; los que registraron menor rezago, Coahuila, Ciudad de México y Aguascalientes. Cabe mencionar que utilizaron 5 grados de rezago social: muy bajo, bajo, medio, alto y muy alto rezago social.
Con base al análisis exploratorio del presente estudio, el IRS mostró que los indicadores con la incidencia más alta fueron el de la población de 15 años y más con educación básica incompleta (29.6%), el de las viviendas que no disponen de lavadora (27.2%) y la falta de derecho habiencia a servicios de salud (26.2%). En cambio, los indicadores mejor posicionados en cuanto a carencia social fue la población de 15 años y más analfabeta (4.7% del total) y población entre 6 y 14 años que no va a la escuela, con 6.1% del grupo. En cuanto a carencia de bienes, las de menor rezago fueron falta de energía eléctrica (0.8% del total). Usando dos técnicas de agrupamiento óptimo (análisis k-means y agrupamiento jerárquico) para clasificar las unidades o entidades federativas en categorías. El resultado fue la generación de tres grados de rezago social: Alto, Medio y Bajo.
Un total de 13,217 millones de mexicanos, que representan al 10.3% del total, viven en los tres estados clasificados como alto rezago social: Guerrero, Chiapas y Oaxaca. En contraste con el 15.4 % de la población que viven en los 8 estados clasificados como rezago social medio, siendo los de menor rezago social 21 estados; Aguascalientes, Coahuila, Nuevo León, CDMX, Jalisco, Guanajuato, Zacatecas, Chihuahua, Baja California Norte y Sur, Tamaulipas, Colima, Sinaloa, Querétaro, Sonora, Quintana Roo, Durango, Nayarit, San Luis Potosí, Campeche y Yucatán. Como puede verse los resultados del presente estudio son muy similares a la estimación realizada por el CONEVAL, demuestra la eficacia de las tecnicas de aprendizaje no supervizado de Maching Learning, además, se cumple la hipótesis de que los estados o entidades federativas localizados en el centro del país se han desarrollado más, que aquellos ubicados en zonas fronterizas o en litorales.
Esto puede tener un origen multifactorial que engloba aspectos como una deficiente redistribución de los ingresos, la concentración de poder en unos cuantos, la falta de políticas públicas incluyentes, corrupción, etc. Denisse Yssel Ortega Leal (2014) señala en su tesis un factor del problema, un estudio sobre los hogares con jefaturas femeninas y su relación con el rezago social en Ciudad Júarez, Chihuahua, reveló que la heterogeneidad que existe dentro de las áreas urbanas del país, las consecuencias de las crisis económicas tuvieron repercusiones significativas en las zonas fronterizas, en comparación con otras áreas urbanas no fronterizas, debido a la fuerte dependencia de el primero sobre la economía estadounidense. Las altas tasas de desempleo registradas dentro de la ciudad hicieron que la pobreza urbana retomara características únicas.
Sin embargo, más allá de las causas, es importante reconocer el problema cuando se manifiesta y sobre todo identificar la población, ya sea por sus características sociodemográficas, su ubicación, o bien por ambas, que presentan un rezago en los aspectos económicos y sociales. Hacerlo resulta fundamental tanto por un tema de justicia social, como para evitar que esto mismo se convierta, más adelante, en un freno para el crecimiento y el desarrollo del Estado.
Referencias
- Arguello, A. (2012). Enfoque factorial en las finanzas públicas un análisis del FISM y el FAFM del RAMO 33 en el estado de Veracruz [Tesis doctoral]. Universidad Veracruzana.
- CONEVAL, Consejo Nacional de Evaluación de la Política de Desarrollo Social, 2020, Índice de rezago social publicado en Internet https://www.coneval.org.mx/Medicion/IRS/Paginas/Indice_Rezago_Social_2020.aspx , México.
- Facultad Latinoamericana de Ciencias Sociales (FLACSO). (2004). Desigualdad social: ¿Nuevos enfoques, viejos dilemas? Cuaderno de Ciencias Sociales(131).
- Maldonado, F. J. B., & Meza, M. V. G. (2013). El rezago social en áreas metropolitanas de México. Estudios económicos, 265-297.
- Mendoza-González, M. F. (2021). Rezago social y letalidad en México en el contexto de la pandemia de enfermedad por coronavirus (COVID-19): una aproximación desde la perspectiva de la salud colectiva en los ámbitos nacional, estatal y municipal. Notas de Población.
- Ortega., D. (2014). Análisis espacial de los hogares con jefaturas femeninas y su relación con el rezago social en Ciudad Juárez Chih., (2000-2010) [Tesis para concluir maestría]. UNIVERSIDAD AUTÓNOMA DE CIUDAD JUÁREZ.
- Rovirosa, J. E. C., Sosa, F. A. P., & Santana, M. A. E. (2017). La relación entre la inclusión financiera y el rezago social en México. Cimexus, 10(1), 13-31.
- Vintimilla, C., Astudillo-Salinas, F., Severeyn, E., Encalada, L., & Wong, S. (2017). Agrupamiento de K-medias para estimación de insulino-resistencia en adultos mayores de Cuenca. Maskana, 8, 31-39.
- Yamamoto, M., & Terada, Y. (2014). Functional factorial K-means analysis. Computational statistics & data analysis, 79, 133-148.
- Código en R-Studio de este proyecto se encuentra publicado en Rpubs. Disponible en: RPubs - Algoritmos no supervisados
Anexos
Código R
# Paqueterias necesarias
library(dplyr)
library(readxl)
library(aplpack)
library(cluster)
library(purrr)
library(ggplot2)
library(factoextra)
library(NbClust)
library(tidyr)
library(readr)
library(kableExtra)
library(FactoMineR)
library(dendextend)
library(leaflet)
library(sf)
library(viridis)
library(RColorBrewer)
library(dplyr)
library(htmlwidgets)
#Base de datos
ruta = file.choose()
datos = read.csv(ruta,header = T)
datos = datos[-1,]
datos = datos[1:32,-1]
rownames(datos) = datos$ent
datos = datos[,c(-1,-2,-17)]
head(datos[,14])
datos$grs = factor(datos$grs)
clasificacion = datos$grs
datos = datos[,-14]
# Datos sin estandarizar y sin la variable población
sndatos = datos[,-1]
boxplot(sndatos)
distancias = get_dist(sndatos,method = "euclidean")
fviz_dist(distancias,gradient = list(low ="blue", mid = "white", high = "red"))
fviz_nbclust(x = sndatos, FUNcluster = kmeans, method = "wss", k.max = 10, diss = get_dist(sndatos, method = "euclidean"), nstart = 32)
# Información de los centroides
set.seed(123)
km_clusters <- kmeans(x = sndatos, centers = 3, nstart = 32)
k3 <- kmeans(sndatos, centers = 3, nstart = 32)
# Comparativa de los indicadores vs clústers
table(clasificacion,k3$cluster)
fviz_cluster(k3, data = sndatos)
# ANÁLISIS JERÁRQUICO
ruta = file.choose()
datos = read.csv(ruta,header = T)
datos<-filter(datos,anio == 2020)
datos<- datos[-1, ]
rownames(datos)<-paste(datos$ent)
datos<-datos[ ,-c(1:4)]
sum(is.na(datos))
datos<-datos[ ,-c(13:14)]
datos<- na.omit(datos)
boxplot(datos,color =c(1,2,3,4,5,6,7,8,9,10,11,12))
# Enlace completo-distancia euclidiana
hccompleto<- hclust (dist(datos), method="complete")
# Enlace promedio
hcmedio <- hclust(dist(datos), method="average")
# Enlace simple
hcsimple <- hclust(dist(datos), method="single")
# Enlace centroide
hccentro <-hclust(dist(datos), method="centroid")
# Enlace Ward
hcward <-hclust(dist(datos), method = "ward.D")
# Dendograma
plot(hccompleto,main="Complete Linkage ", xlab="", sub="",cex=.9)rect.hclust(hccompleto, k=3, border=3)
plot(hcmedio,main="Average Linkage ", xlab="", sub="",cex=.9)rect.hclust(hcmedio, k=3, border=3)
plot(hcsimple,main="Single Linkage ", xlab="", sub="",cex=.9)rect.hclust(hcsimple, k=3, border=3)
plot(hccentro,main="Centroide Linkage ", xlab="", sub="",cex=.9)rect.hclust(hccentro, k=3, border=3)
plot(hcward,main="Ward Linkage ", xlab="", sub="",cex=.9)rect.hclust(hcward, k=3, border=3)
fviz_dend(x = hcward, k = 3, rect = TRUE, cex = 0.6, palette = "lancet") + labs(title = "Ward Linkage", subtitle = "Distancia euclídea, Lincage Ward, K=3")
# Visualizar clúster
D <- cutree(hcward, k=3)
fviz_cluster(list(data=datos, cluster=D))
# ELABORACIÓN DEL MAPA- DESCARGAR "gadm36_MEX_1.shp"
root <- 'ubicación del archivo en su ordenador'
shape <- st_read(paste0(root, "/gadm36_MEX_1.shp"))
isrnumero <- datos$irs
shape$numerica <- isrnumero
shape$categorica <- case_when(shape$numerica < -0.298102 ~ "Bajo", shape$numerica >= -0.298102 & shape$numerica < 2.4 ~ "Medio", shape$numerica >= 2.4 ~ "Alto") # Información resultante del análisis k-medias y análisis jerárquico.
palnumeric <- colorNumeric("viridis", domain = shape$numerica)
palQuantile <- colorQuantile("Spectral", domain = shape$numerica)
palfac <- colorFactor("RdBu", domain = shape$categorica)
popup <- paste0("", "Nombre estado: ", "", as.character(shape$NAME_1), "", "", "Grado de Rezago Social: ", "",shape$categorica,"")
# Función para crear el mapa
mapa <- leaflet(shape) %>% addProviderTiles("Esri.WorldTerrain") %>% addPolygons(color = "#444444", weight = 1, smoothFactor = 0.5, opacity = 1, fillOpacity = 0.5, fillColor = ~palfac(shape$categorica), group = "ISR", highlightOptions = highlightOptions(color = "white", weight = 2, bringToFront = TRUE), label = ~shape$NAME_1, labelOptions = labelOptions(direction = "auto"), popup = popup) %>% addLegend(position = "bottomleft", pal = palfac, values = ~shape$categorica, title = "Grado de Rezago Social") %>% addPolygons(data = shape, color = "#444444", weight = 1, smoothFactor = 0.5, opacity = 1, fillOpacity = 0.5, fillColor = ~palnumeric(shape$numerica), group = "Grado", highlightOptions = highlightOptions(color = "white", weight = 2, bringToFront = TRUE), label = ~shape$NAME_1, labelOptions = labelOptions(direction = "auto"), popup = popup) %>% addPolygons(data = shape, color = "#444444", weight = 1, smoothFactor = 0.5, opacity = 1, fillOpacity = 0.5, fillColor = ~palQuantile(shape$numerica), group = "Porcentaje", highlightOptions = highlightOptions(color = "white", weight = 2, bringToFront = TRUE), label = ~shape$NAME_1, labelOptions = labelOptions(direction = "auto"), popup = popup) %>% addLegend(position = "bottomright", pal = palQuantile, values = ~shape$numerica, title = "Cuantiles de ISR") %>% addLayersControl(baseGroups = c("ISR", "Grado", "Porcentaje")) %>% addLegend(position = "topright", pal = palnumeric, values = ~shape$numerica, title = "Indice de Rezago Social")
# Imprimir el mapa
mapa
# Guardar el mapa
htmlwidgets::saveWidget(mapa, "mapa.html")